Hierarchical Neural Program Synthesis
Linghan Zhong¹, Ryan Lindeborg¹, Jesse Zhang¹, Joseph J. Lim² ³, Shao-Hua Sun⁴ ¹USC, ²KAIST, ³AI Advisor at Naver AI Lab, ⁴National Taiwan University
Recent works in program synthesis have demonstrated encouraging results in a variety of domains such as string transformation, tensor manipulation, and describing behaviors of embodied agents. Most existing program synthesis methods are designed to synthesize programs from scratch, generating a program token by token, line by line. This fundamentally prevents these methods from scaling up to synthesize programs that are longer or more complex. In this work, we present a scalable program synthesis framework that instead synthesizes a program by hierarchically composing programs. The experimental results demonstrate that the proposed framework can synthesize programs that are significantly longer and more complex than the programs considered in prior program synthesis works.
Method Overview
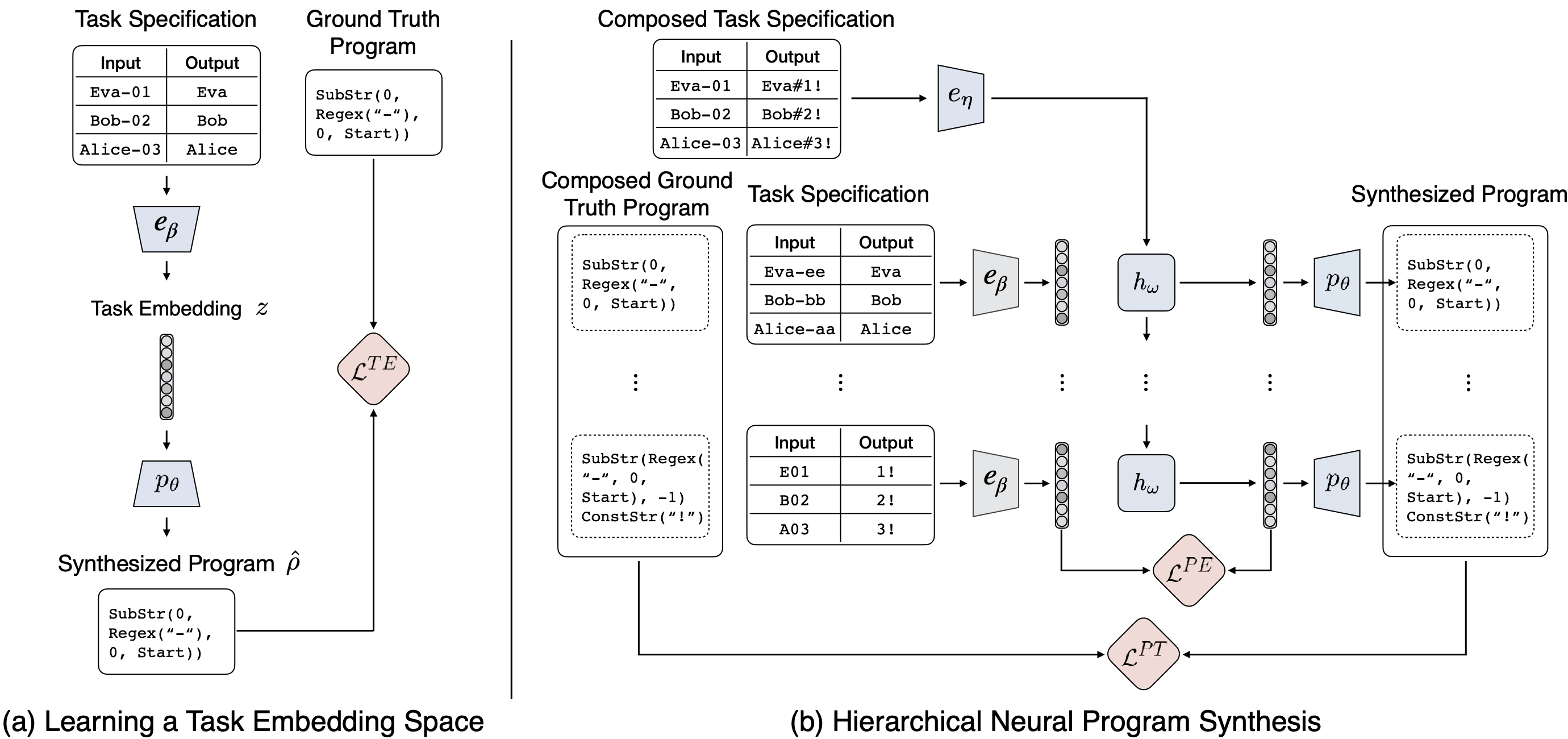
In this work, we aim to develop a program synthesis framework that can scale up to longer programs which can induce more complex behaviors. Our key idea is to compose shorter programs with simple behaviors to form longer programs with more complex behaviors.
To this end, we introduce a two stage training framework:
- Learning program embedding stage: We construct a short program dataset that contains short programs with their corresponding input/output pairs. Then, we learn a task embedding space that represents the space of short program behaviors, along with a program decoder that can decode a task embedding into a short program.
- Learning program embedding stage: We create a composed program dataset in which the composed programs are generated by sequentially composing short programs. We then train a “program composer” on this dataset to produce a sequence of task embeddings, each representing a latent short program, which are decoded by the program decoder into short programs and sequentially composed to yield the synthesized program.
This training schema allows for generating programs via program-by-program composition rather than token-by-token composition, thus enabling additional supervision through the task embeddings instead of only maximizing the likelihood based on produced program tokens.
String Transformation

Programs considered in this work are constructed based on a Domain Specific Language (DSL) for string transformation tasks. The DSL establishes the possible space of valid programs as well as en- ables sampling programs. An example of our DSL is shown in the figure above. The DSL defines a set of operations
(e.g. SubStr(k₁, k₂), Concat(e₁, e₂, ...),
ConstStr(s))
and their parameters, such as numbers (e.g k₁, k₂) and strings (e.g s).
A program consists of a sequence of expressions which would output a sub-string of the input string or a constant string. The output of the expressions would then be concatenated to produce the final output string of the program.
For example, a program Concat(SubStr(0, 1), ConstStr("!"))
takes an input string John-01
and produces an output string J!.
Experiments
Performance on Unseen Test Programs
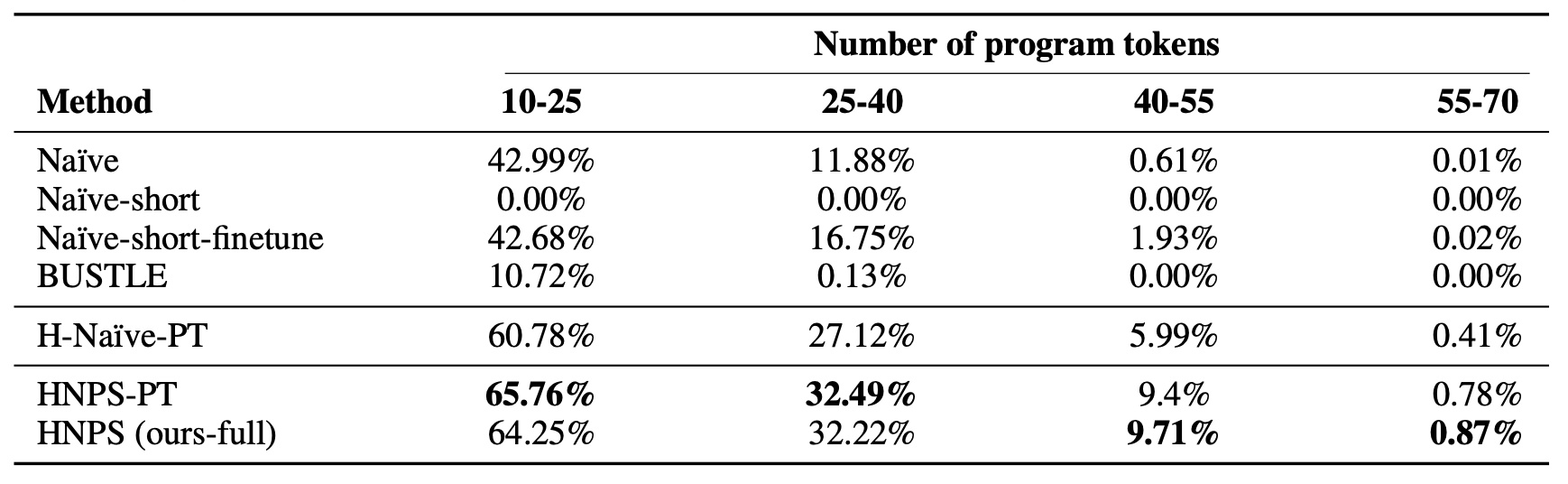 We evaluate execution accuracy over unseen test programs in our dataset $D_\text{long}$, where execution accuracy refers to the percent of synthesized programs that produce the correct output for all given input strings. The x-axis represents the length of the ground truth program (number of program tokens). The results are shown in the table above.
We evaluate execution accuracy over unseen test programs in our dataset $D_\text{long}$, where execution accuracy refers to the percent of synthesized programs that produce the correct output for all given input strings. The x-axis represents the length of the ground truth program (number of program tokens). The results are shown in the table above.
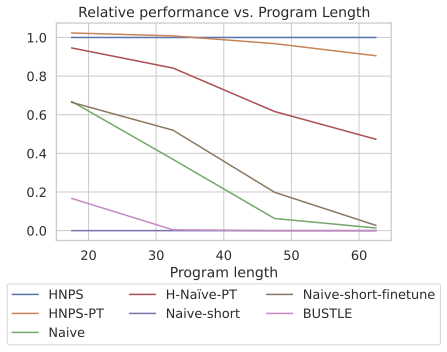
We additionally provide a visualization of relative performance on different program lengths in the figure above where we normalize the execution accuracy of each method by scaling the accuracy of HNPS to 1.0.
We observe that HNPS can generalize especially well to longer program with more than 40 tokens compare to baseline methods.
Analyzing the Task Embedding Space
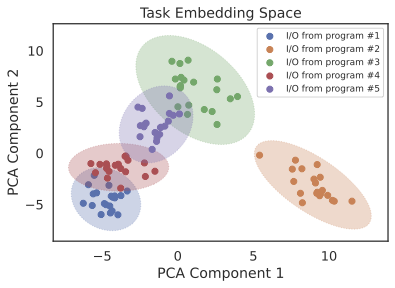
We provide a visualization of the tasks embeddings of 5 programs randomly drawn from the test set of $D_\text{short}$. Dimensionality reduction is performed with principal component analysis (PCA) in order to project the task embeddings to a 2D space. We represent one embedding of an I/O pair with a dot in the figure and represent different programs using various colors. As shown in the figure, I/O pairs from the same program are clustered together and I/O pairs from different programs are separable, demonstrating that a meaningful embedding space is able to be learned and leveraged in our training procedure.
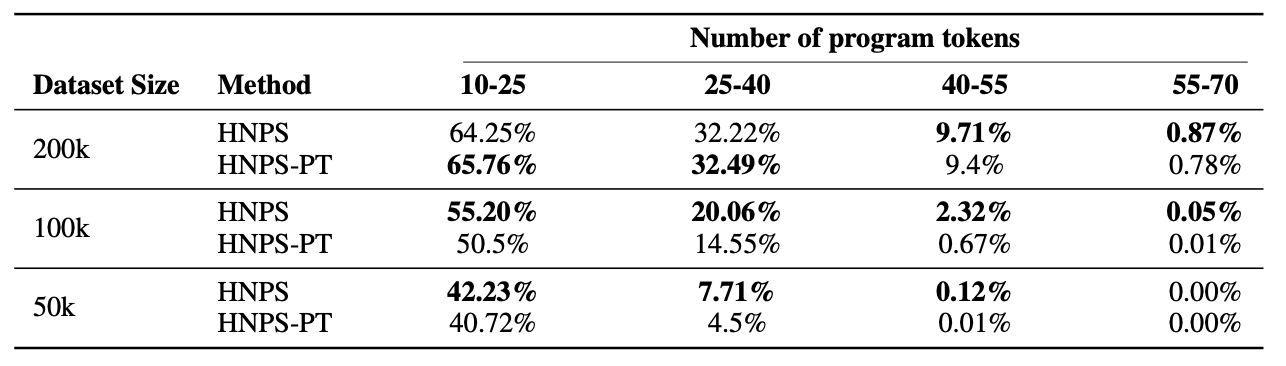
Ablating the Program Embedding Loss
In Table above we compare HNPS, our full method, and HNPS-PT, our method without the program embedding loss $\mathcal{L}^{\text{PE}}$, on $D_\text{long}$ as a function of the size of the composed program dataset. When trained with the full $D_\text{composed}$, HNPS only performs better than HNPS-PT on programs longer than 40 tokens. However, when using 50% or 25% of the data, HNPS’s performance become significantly better than HNPS-PT across all program lengths. This suggests that the supervision from program embedding loss is particularly effective when data is scarce.